
我们考虑要做一个大数据平台,就需要先搞清楚我们的需求是什么。我认为主要有以下四点:
只要通过这两条SQL就可以完全实现计算任务开发,那它跟离线计算结果有什么不一样呢?它实时输出结果,而离线是一次性输出结果,提交这样的SQL就不停的输出销售额的分类统计。
在一些相关工具上,我们以自研来满足用户需求,我们做的事情主要包括Kafka服务化,我们把Kafka做成云服务的方式,在日志收集方面做了Data Stream系统,主要功能是把日志收集到大数据平台并转成Hive表。我们也做了数据库同步工具,完成数据库到数据库,数据库到大数据系统之间的同步。
此外,我们也做了kudu Tablet Split自动分裂功能,主要对Ranger分区做了分裂,分裂思路比较简单,主要是修改元数据,整个过程瞬间在线完成,不会涉及数据真正的变更,。具体做法是在元数据上标识将一个Tablet分为两个,此后都遵循该原则,但只有在Compaction时才会发生真正的物理分裂。
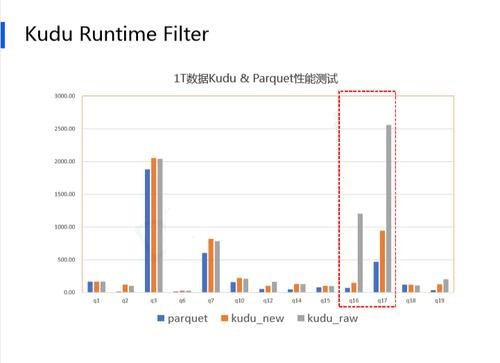
3、Kudu:实时更新存储
三是支持SparkContext的动态缓存。创建一个SparkContext耗时较长,所以我们要对SparkContext进行缓存设置,让用户不需要每次查询都动态创建SparkContext。
在这个任务下假设我们输入的数据有四条(如下图):第一个商家交易额30,然后第二个商家交易额10,第三个商家交易额80,再来第三个商家交易额50,我们来看看用不同的计算引擎出来的计算结果有哪些差异。
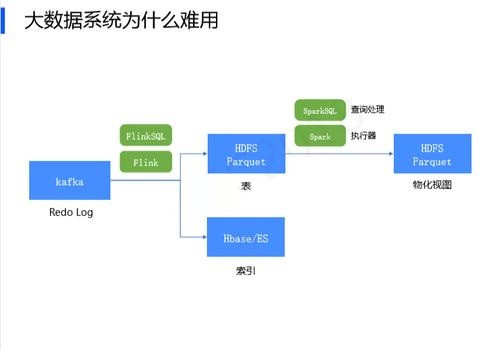
数据从Kafka出发,通过Flink处理同时写入HDFS和HBase。HDFS的数据经过Spark进一步处理最终将汇总数据返回HDFS,传递给BI软件进行展示或者为线上数据提供支持。如果将大数据系统与数据库内核做对比,我们发现Kafka其实类似于数据库中的Redo log,Hbase/ES代表一个索引,经过进一步汇总最终形成物化视图HDFS Parquet。
整个平台主要有四大特点:
四是多租户安全,大数据平台服务于整个公司,公司内部多条业务线都会使用,多租户安全是必备功能。
在这些需求之下,网易大数据最终的整体架构如下:
在效果上,我们做到了Exactly Once跟增量计算模型,通过实时计算SQL算出来的结果跟用离线计算出来的结果一样,这是对数据正确性的重要保证。当然,Sloth也是在猛犸大数据平台上开发的。
Kyuubi基于Spark Thrift Sever改造,Spark Thrift Sever类似于HiveSever2,但是它不够完善。由于我们在此基础上增加了多租户的功能,因此可以支持网易内部各业务线的使用。要想实现多租户功能,首先要把SparkContext变成多实例,之后每次执行代理真正的用户身份执行;其次,我们提供了Spark SQL集群,用户请求负载均衡到每台Kyuubi服务器,并且这部分是高可用的,一台服务器挂了会立刻切换到另一台。
免责声明:凡本网注明 “来源:XXX(非中国房产新闻网)” 的作品,均转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。
 分享到:
分享到:







